1. introduction
fake news has been present in the society for a long time, but recent advances in social media platforms and technology, in general, have allowed these news articles to propagate very fast. fake news, defined by the New york times as “a made-up story with an intention to deceive, often for a secondary gain,” is arguably one of the most serious challenges facing the news industry today. in a December pew research poll, 64% of us adults said that “made-up news” has caused a “great deal of confusion” about the facts of current events. it is challenging and even unrealistic to identify rumors and hoaxes in the information age relying only on the traditional human-based fact checkers, due to both the tremendous scale and the real-time nature. but the good thing is, we can leverage on sophisticated machine learning / deep learning techniques for the problem of such high scale.
in this project, we are planning to develop a stance detection tool that can automatically reason about the relationship between a new headline and body text. in other words, the task is to identify whether a headline-article body pair agrees, disagrees, discusses, or unrelated . this project is inspired from fake news challange and we are also using the database provided by fnc . this tool can be used as a building block to develop an automated veracity checker which can quickly check the veracity of a new claim based on the agreement with the claims made by other news organization with the known level of reliability and bias. Following figure depicts the problem with an example.

2. Related Work
Since the fake news dataset we are using for this project is new, there are not enough papers to address this dataset. However, the stance detection and text classification tasks are thoroughly studied.
Research in [1] is closely related to our problem where stance detection has been carried out on Twitter tweets. Given the tweet and the target - i.e., a politician, the goal is to estimate whether the tweet is in favor, against, or neutral toward the given target. The task is quite similar to our problem, where given the News headline and corresponding article body, we have to predict whether article body is agreeing, disagreeing, discussing or unrelated to the headline. In twitter stance detection, they are using bi-directional LSTM to read tweet condition on the target.
- Baseline Model
The organizers of Fake News Challenge have provided a baseline model where they extracted features from the headline and body and passed it to a gradient boosting classifier. On the train set, they achieved an accuracy of 77%, and on the test set, they achieved an accuracy of 75%.
3. Our Approach
As a part of our project, we have experimented with two different approaches for the problem of stance detection -
-
In this approach, we are using Long Short-term Memory Network that conditions the analysis of headline on the article representation. The hope is that, LSTM will capture the context (and therefore stance/opinion) of the headline and body separately. LSTM is followed by a simple feedforward network that will train itself to decide whether the opinion/stance expressed in the News headline matches with opinion/stance expressed in News article body.
-
In this approach, we are extracting different features from the News headline as well as News body. Features include standard features used in NLP such as TF-IDF , N-grams , cosine similarity as well as some handpicked features such as presence of refuting words. Full list of features is given below.
3.1 Sequential/Dynamic Approach :
Let (xh1,xh2, xh3, …., xhn) denote the sequence of word vectors corresponding to the words in the headline and (xa1,xa2, xa3, …., xan) denote sequence of words in the article. Each word in the sequence is represented by a D dimensional embedding that was obtained from pretrained Stanford Global word vectors (GloVe) . We separately encode the headline and body text. Firstly, we pass the headline embeddings to the first encoder and obtain an encoding H = [h1, h2, …., hn] and then we pass the article body to the second encoder to obtain an encoding A = [a1, a2, …., an]. Encodings tend to represent context information inside the News article and body. These encodings are appended and passed to a feedforward network, which further classifies the Headline-Body pair into 4 classes - agree, disagree, discuss, unrelated. Following figure depicts the model architecture.
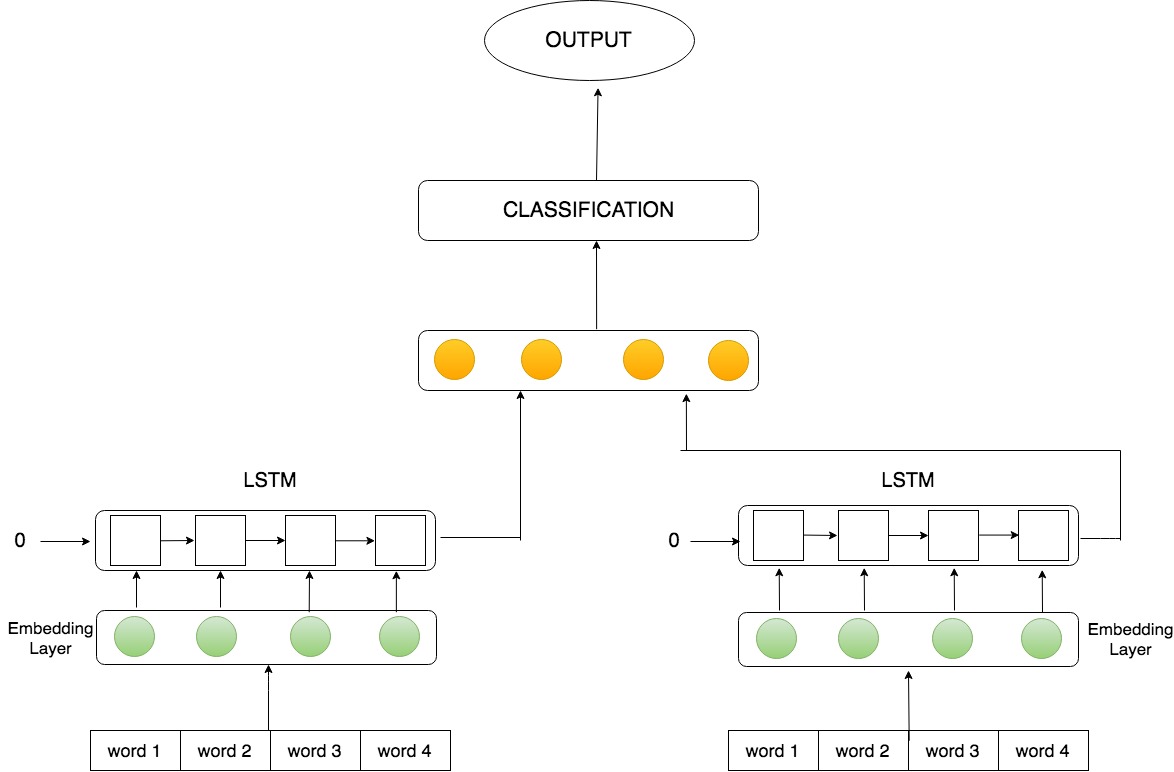
- Results:
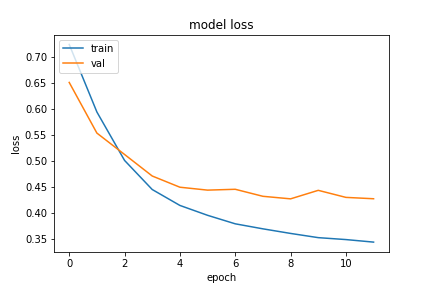
We experimented with different sequence lengths - defined as number of words in the News article body fed to LSTM. Truncation of articles to specific length is required for batch processing since different articles have different lengths. Apart from sequence lengths, we also experimented with hyperparameters of LSTm - no of GRUs, layers, pre-trained/BOW embeddings. We were able to achieve the best case accuracy of 72.30% on sequence length of 600, 200 LSTM cells, dropout probability of 0.5 , learning rate of 0.01. Following figures show the learning curve for training/validation datasets and confusion matrix for testing dataset.
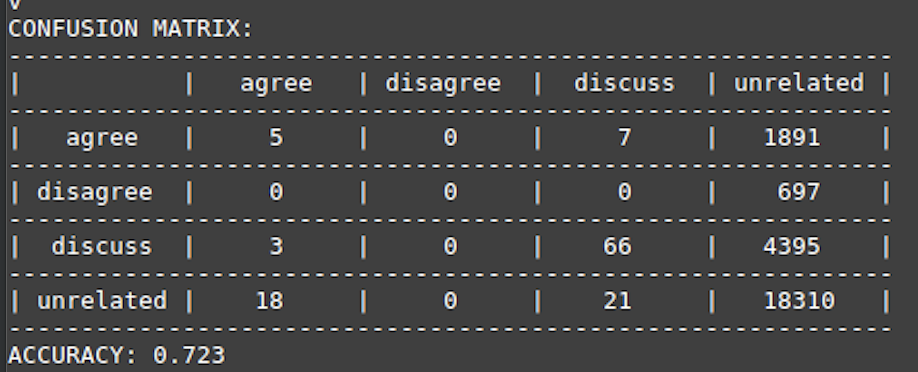 ……………………….
………………………. 
3.2 Static Approach :
In this approach, we are extracting following features and training a Feed-forward network on these features.
-
Cosine similarity: - Firstly the headline and body are converted to TF-IDF form and then cosine similarity is calculated between them.
-
Word overlap: This feature depicts overlap between News headline and News Body. Higher the overlap, more the certainty that body of the News article agrees with headline.
-
Presence of refuting words: If the news article contains refuting words such as ‘fraud’, ‘hoax’, ‘deny’, it wouldn’t inspire much confidence into the news article.
-
Polarity: The polarity of headline and body is determined by counting number of negative sentiment words. We used NRC word-emotion Association Lexicon is used to obtain a list of negative emotions associated with English words. Polarity of corpus is assigned based on whether it has odd/even number of negative words.
-
Discuss Features: In this feature we are detecting presence of “discuss” words in the news article viz. tell, claim, verify etc.
-
Common N-Grams : This features indicates the extent of commonality in terms of N-grams between headline and body. We experimented with N=2,3,5,6 grams.
-
Binary co-occurrence: This feature counts how many times token in the headline occurs in body.
-
TF-IDF : In addition to all above features, we are also feeding raw TF-IDF of headline and body to the feedforward network.
All the above features are appended and given to a feedforward network. Following figure depicts the model architecture and feature vector.
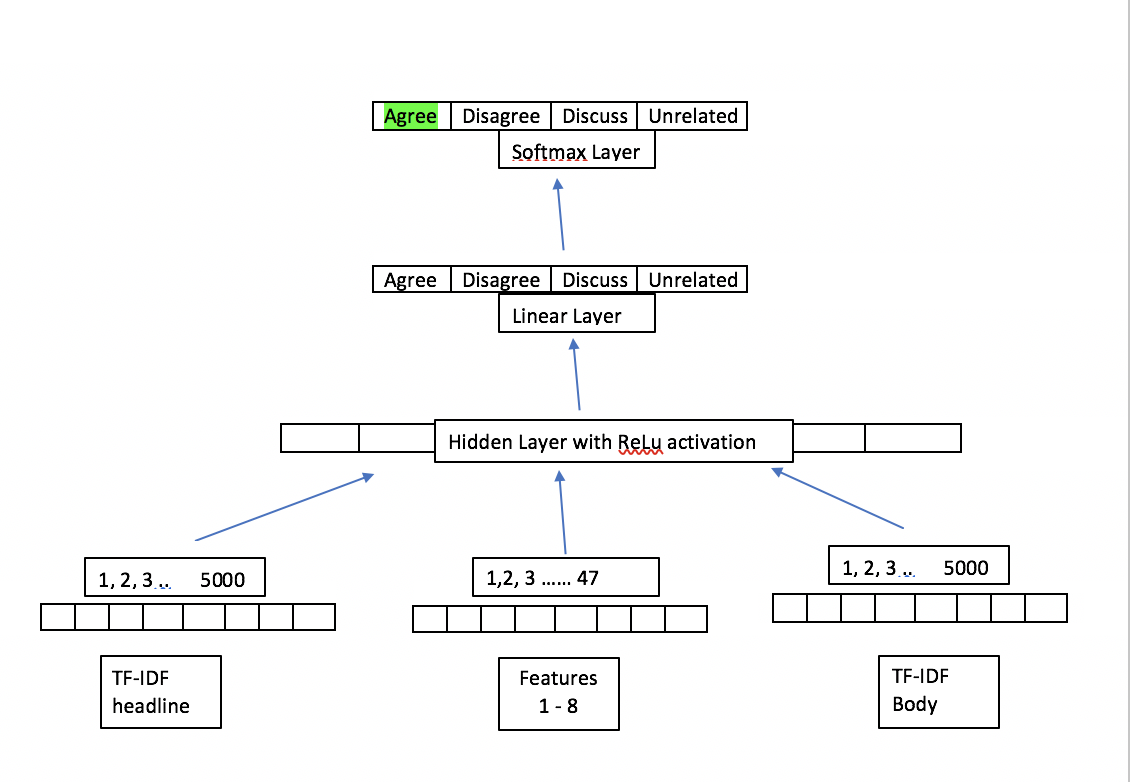
- results :
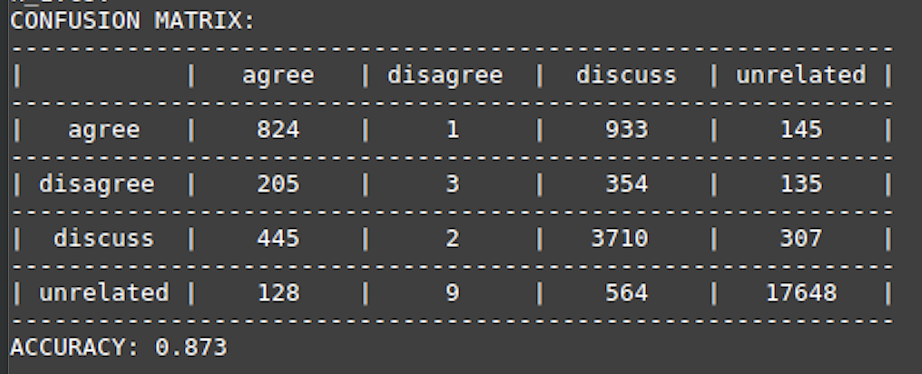
We were able to achieve 87.30 % accuracy on test set after experimenting with different hyperparametrs. Following image shows the confusion matrix of the test set.
4. Accuracy Comparison
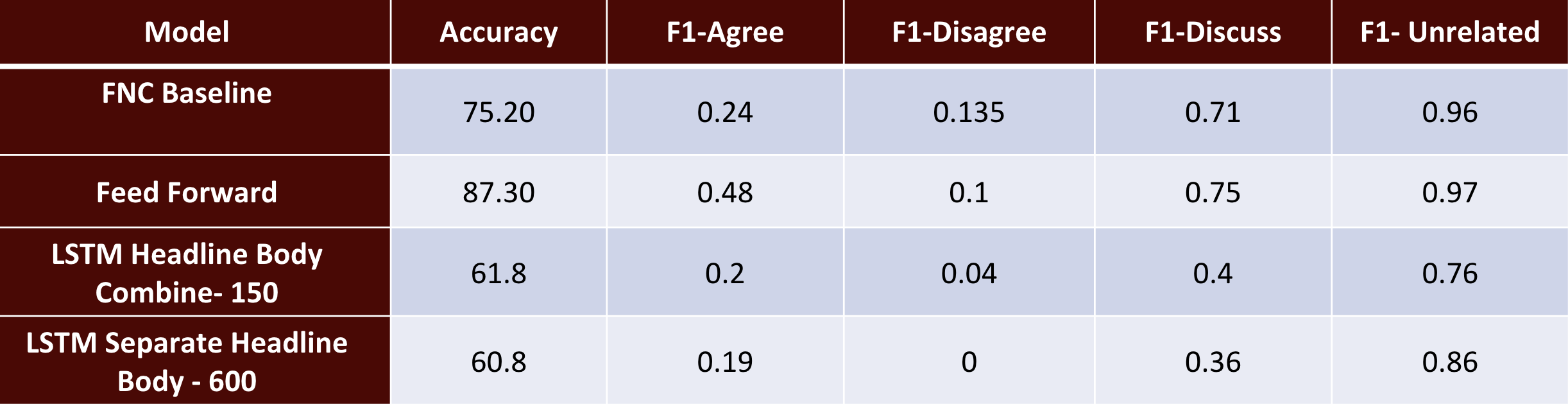
Following table gives the performance comparison of different approaches.
5. Conclusion and Future Work :
Honestly, we were surprised to see a simple feedforward network achieving higher accuracy than sophisticated LSTM model with pre-trained embeddings. We could account this to good feature engineering. Our hope before training LSTM was that, it should be able to extract the relevant features on it’s own as it captures the context. But clearly, manual feature engineering is giving us significant increase in accuracy. Now, the obvious question is, why didn’t we try feeding engineered features to LSTM, and the simple answer is time restrictions. Three weeks is a really short time frame to implement the models, tune hyperparameters and conduct experiments. Nevertheless, this is something we definitely plan to do in the future. Secondly, we are really eager to try out bi-directional LSTM for this task. Advantages of bi-directional sequential models are well-known over uni-directional models, and this is something we definitely have in our bucketlist. Thirdly, we could always improve upon feature engineering and we plan to extract more relevant features for this task.
6. References:
[1] Isabelle Augenstein, Tim Rocktaschel, Andreas Vlachos & Kalina Bontcheva. 2016. Stance detection with bidirectional conditional encoding. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (EMNLP).
[2] I. Augenstein, T. Rocktaschel, A. Vlachos, and K. Bontcheva. Stance detection with bidirectional conditional encoding. In EMNLP, 2016.
[3] M. Babakar. Fake News Challenge, 2016.https://http://www.fakenewschallenge.org/.
[4] W. Ferreira and A. Vlachos. Emergent: a novel data-set for stance classification. In HLT-NAACL, 2016.
[5] Y. Goldberg and O. Levy. word2vec explained: deriving mikolov et al.’s negative-sampling word-embedding method. CoRR, abs/1402.3722, 2014.
[6] T. Mikolov, K. Chen, G. S. Corrado, and J. Dean. Efficient estimation of word representations in vector space. CoRR, abs/1301.3781, 2013.
[7] B. Riedel, I. Augenstein, G. P. Spithourakis, and S. Riedel. A simple but tough-to-beat baseline for the fake news challenge stance detection task. CoRR, abs/1707.03264, 2017. [8] Q. Zeng, Q. Zhou, and S. Xu. Neural stance detectors for fake news challenge. 2017. [8] UCL Machine Learning - https://github.com/uclmr/fakenewschallenge
[9] GloVe: Global Vectors for Word Representation https://nlp.stanford.edu/projects/glove/
[10] Keras: The Python Deep Learning library https://keras.io/